Checkpoint
Use checkpointing at regular intervals for networks with long training times.
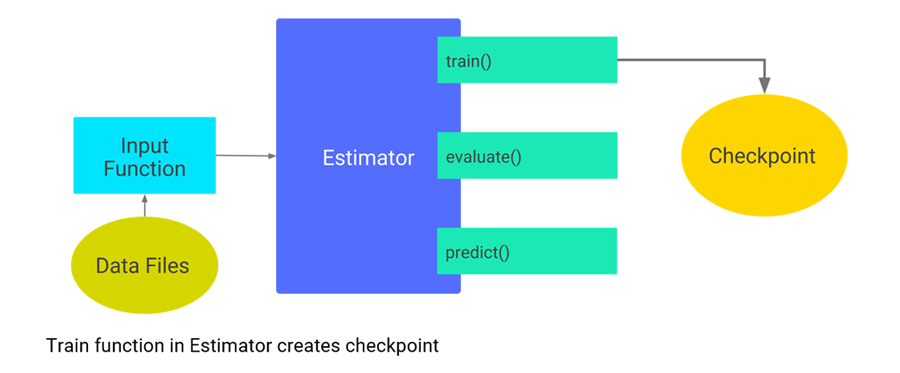
Context: The training duration of some deep learning models can be very long, ranging from several hours to several months even with the use of powerful hardware. This would require the training hardware running for a long duration without any breakdown. Failure in hardware, interruption in the power supply, or errors in the software may cause termination of the training process before it completes.
Problem: Incomplete training due to termination of the process leads to the loss of knowledge gained during the training. This would render the energy spent on the training process useless. Subsequent retraining would require the process to start from scratch.
Solution: Checkpointing is a fault tolerance technique used in long processes. In neural networks, checkpointing lets the users save the intermediate model state generated during the training process. In case of a failure, the users can resume the training process from the latest checkpoint instead of restarting from scratch. While checkpointing at regular intervals may come with a few overheads of its own, it can help save energy wastage caused by termination of long training process due to faults.
Example: Consider a model that requires several hours of training on a preemptible instance to get decent results. Since the preemption may occur in the middle of the training, not having a check- point would lead to the loss of knowledge gained during the process since the training cannot be resumed from the point of preemption. Having checkpoints would preserve the state of the model at regular intervals and the training could be resumed from the latest checkpoint in the case of a preemption. This would save the energy wastage caused by loss of knowledge due to the interruption in the training. The example is taken from this Stack Overflow post.
- https://stackoverflow.com/questions/44835223/
- https://stackoverflow.com/questions/41465681/
- https://stackoverflow.com/questions/64419191/
- https://stackoverflow.com/questions/42621864/
- https://stackoverflow.com/questions/51170644/
- https://stackoverflow.com/questions/60115848/
- https://stackoverflow.com/questions/41992132/
- https://stackoverflow.com/questions/39757985/
- https://stackoverflow.com/questions/41621071/
- https://stackoverflow.com/questions/61470732/
- https://stackoverflow.com/questions/52874647/
- https://stackoverflow.com/questions/53127232/
- https://stackoverflow.com/questions/65987683/