Distillation
If pre-trained models are too large for a given task, apply knowledge distillation or use distilled versions of pre-trained models
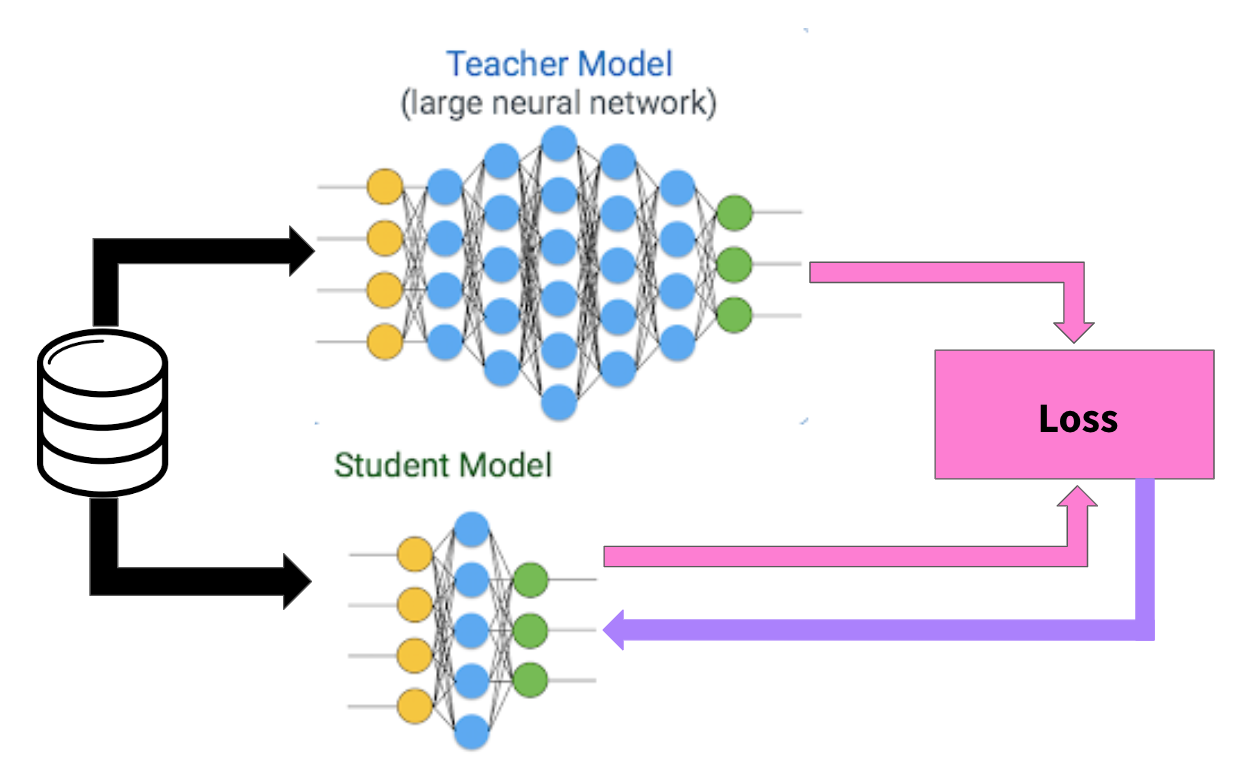
Context: Use of pretrained models can save the energy spent on training a new network from scratch. However, these models can sometimes be too large for the given task and given power consumption and resource constraints.
Problem: Using pretrained models that are too large for a given task may cause excessive computations and memory access due to the number and size of model parameters. This leads to increased power consumption during fine tuning and inferencing.
Solution: Knowledge distillation refers to the process of transferring the knowledge from a larger model to a smaller one. It involves training a smaller model called student to mimic a larger pre-trained model called teacher using an appropriate loss function. It solves the problem of expensive inferencing caused by larger pre-trained models.
Example: Consider a classification task that needs to classify movie reviews. A pretrained model like BERT with some fine-tuning can be used without having to train the model from scratch. However, if a minor compromise in the accuracy can be tolerated, a distilled version of BERT model called DistilBERT can be used with some fine-tuning. Due to its smaller size, DistilBERT can be much more energy-efficient for fine-tuning and inferencing.
- https://stackoverflow.com/questions/44236449/
- https://stackoverflow.com/questions/63201036/
- https://stackoverflow.com/questions/68322542/
- https://stackoverflow.com/questions/68380183/
- https://stackoverflow.com/questions/61402903/
- https://stackoverflow.com/questions/68928299/
- https://stackoverflow.com/questions/60780181/
- https://stackoverflow.com/questions/61326892/
- https://stackoverflow.com/questions/60056812/
- https://stackoverflow.com/questions/45194954/