Quantization
Use network quantization in applications with memory constraints where a minor loss in performance is acceptable
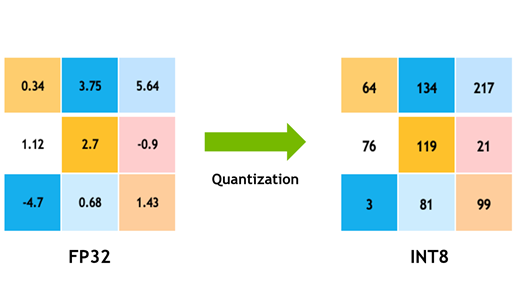
Context: With the rising use of deep learning in different domains, the models are being used on battery powered devices such as smartphones. Doing so is also beneficial from the point of view of bandwidth and latency. However, the large size of these models with their energy consumption requirements can pose a significant challenge in case of battery powered devices
Problem: Running the deep learning models can involve millions of multiplication and addition operations. Having a high precision representation of the parameters causes these operations to become expensive in-terms of energy requirements on battery powered devices.
Solution: Network quantization involves reducing the number of bits to represent the parameters of the neural network. Quantization has been used in the existing work to improve energy efficiency of the deep learning models. Quantizing the network can make the multiplication and addition operations less expensive computationally due to the reduction in the bit-width of the operands. This causes reduction in power consumption. It also cuts down the memory requirements due to the reduction in the model size. If done properly, quantization only causes minor loss in performance and does not affect the output significantly.
Example: Consider an MobileNet V2 model that needs to be deployed on a smartphone. Quantization of the model to use parameters using 4-bit precision can lead to a smaller model size with lesser energy consumption per computation.
- https://stackoverflow.com/questions/54261772/
- https://stackoverflow.com/questions/44311820/
- https://stackoverflow.com/questions/61637457/
- https://stackoverflow.com/questions/53104887/
- https://stackoverflow.com/questions/62490121/
- https://stackoverflow.com/questions/62592265/
- https://stackoverflow.com/questions/63207707/
- https://stackoverflow.com/questions/61083603/
- https://stackoverflow.com/questions/53017722/
- https://stackoverflow.com/questions/56779949/
- https://stackoverflow.com/questions/62450062/
- https://stackoverflow.com/questions/46618583/
- https://stackoverflow.com/questions/65902185/
- https://stackoverflow.com/questions/57234308/
- https://stackoverflow.com/questions/53500185/
- https://stackoverflow.com/questions/63924862/
- https://stackoverflow.com/questions/60998416/
- https://stackoverflow.com/questions/43834533/
- https://stackoverflow.com/questions/64413087/
- https://stackoverflow.com/questions/52259343/
- https://stackoverflow.com/questions/62558666/
- https://stackoverflow.com/questions/57631313/
- https://stackoverflow.com/questions/66731194/
- https://stackoverflow.com/questions/43300000/
- https://stackoverflow.com/questions/66879986/
- https://stackoverflow.com/questions/65626935/
- https://stackoverflow.com/questions/65626935/
- https://stackoverflow.com/questions/65626935/
- https://stackoverflow.com/questions/65626935/
- https://stackoverflow.com/questions/65626935/
- https://stackoverflow.com/questions/65626935/